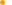 RAID 표준 규격 및 데스크탑 PC에서 쓰이는 비표준 규격 소개 RAID 표준 규격 및 데스크탑 PC에서 쓰이는 비표준 규격 소개

RAID는 일정한 방식에 따라 여러 개의 디스크를 묶는 것이라 그 묶는 원리와 구성에 따라 다양한 조합으로 만들어질 수 있다. 표준 규격은 RAID 0부터 1, 2, 3, 4, 5, 6 등으로 이어지며 이와 다른 중첩(Nested) RAID와 비표준(Non Standard) RAID 레벨인 0+1, 1.5, 인텔 Matrix RAID 등이 있다. 이번 페이지는 다양한 RAID 가운데 표준 규격과 데스크탑 PC에서 많이 사용되는 나머지 규격을 간단히 설명하도록 하겠다.
RAID 0
RAID 0은 일반적으로 2개 이상의 하드를 병렬로 연결해서 데이터를 블록(Block) 단위로 분산해서 읽고 쓰는 방식으로 구성된다. 하나의 데이터를 복수의 하드를 이용해 분산시키기 때문에 하드 1개에 데이터를 저장하고 불러오는 것보다 훨씬 빠른 속도를 가질 수 있게 되며 하드 용량도 모두 쓸 수 있다.
이론상으로는 하드 디스크를 추가할 때마다 계속 성능이 향상되기 때문에 여러 대의 하드를 RAID 0으로 묶으면 하드 자체가 가진 물리적인 성능을 넘어 컨트롤러의 대역폭을 충분히 활용할 수 있는 강력한 드라이브를 구축할 수 있다. 하지만 안정성을 체크하는 기능이 없어 만약 1개의 하드라도 완전히 고장나면 RAID 0으로 구성된 모든 데이터를 전부 날리게 된다.
따라서 서버나 워크 스테이션처럼 RAID가 주로 사용되는 분야에서는 절대 RAID 0만으로는 RAID 시스템을 구축하지 않으며, 미러링이나 패리티 정보 저장 등 다른 방식과 함께 구성해 성능/안정성을 동시에 추구하도록 보완된 RAID 규격을 쓴다.
PC에서도 보존해야 할 중요한 데이터가 있는 경우 RAID 0 하드에 저장하지 않는다는 것이 상식이지만, 데이터 보존용이 아니라 프로그램 설치/실행 및 캐시 용도로 사용한다면 충분히 좋은 성과를 누릴 수 있다. RAID 0 방식이 위험하긴 하지만 심심하면 깨지는 그런 형편없는 수준은 아니다.
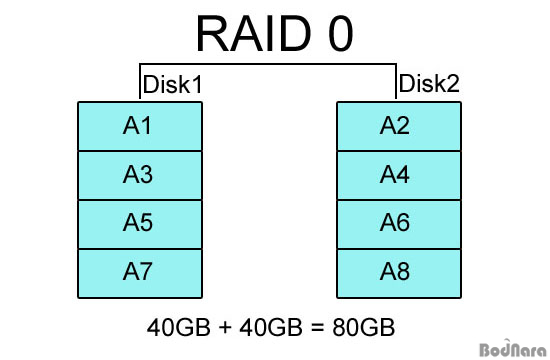
RAID 1
RAID 1은 데이터의 안정성을 높이기 위해 동일한 데이터를 1개 이상의 하드에 똑같이 저장하는 방식으로 RAID 0과는 반대되는 개념이라고 할 수 있다. RAID 1로 구성한 하드는 한 쪽이 망가져도 동일한 데이터가 저장된 다른 하드가 살아있다면 데이터를 복구할 수가 있으며, RAID 구성이 풀리더라도 같은 데이터를 가진 2개의 하드 디스크가 존재하게 된다.
RAID 1은 데이터 안정성은 높지만 2개의 하드를 RAID 1로 묶으면 같은 데이터를 2개에 기록해 전체 하드 디스크 용량의 절반만 사용하게 된다. RAID 1은 2개의 하드 디스크를 1조로 묶는 것을 기본으로 하므로 RAID 1로만 시스템을 구현하지 않고 다른 RAID 방식과 합쳐서 구성하게 된다.
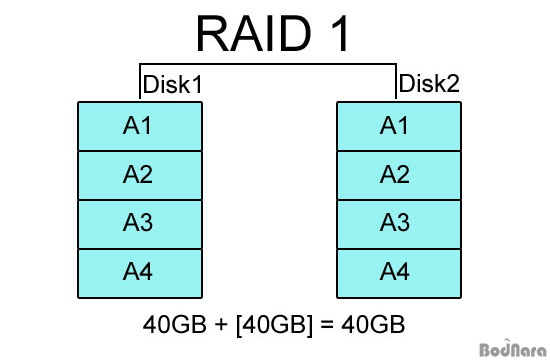
RAID 2
RAID 2는 RAID 0처럼 스트라이핑 방식이지만 에러 체크와 수정을 할 수 있도록 Hamming Code를 사용하고 있는 것이 특징이다. 하드 디스크에서 ECC 기능을 지원하지 않기 때문에 ECC(Error Correction Code)을 별도의 드라이브에 저장하는 방식으로 처리된다.
하지만 ECC를 위한 드라이브가 손상될 경우는 문제가 발생할 수 있으며, 패리티 정보를 하나의 하드 드라이브에 저장하는 RAID 4가 나오면서 거의 사용되지 않는 방식이라고 하겠다.
RAID 3, RAID 4
RAID 3, RAID 4는 RAID 0, 1의 문제점을 보완하기 위한 방식으로 3, 4로 나뉘긴 하지만 RAID 구성 방식은 거의 같다. RAID 3/4는 기본적으로 RAID 0과 같은 스트라이핑(Striping) 구성을 하고 있어 성능을 보완하고 디스크 용량을 온전히 사용할 수 있게 해주는데, 여기에 추가로 에러 체크 및 수정을 위해서 패리티(Parity) 정보를 별도의 디스크에 따로 저장하게 된다.
RAID 3는 데이터를 바이트(byte) 단위로 나눠 디스크에 동등하게 분산 기록하며, RAID 4는 데이터를 블럭 단위로 나눠 기록하므로 완벽하게 동일하진 않다. RAID 3는 드라이브 동기화가 필수적이라 많이 사용되지 않고 RAID 4를 더 많이 쓴다고 한다.
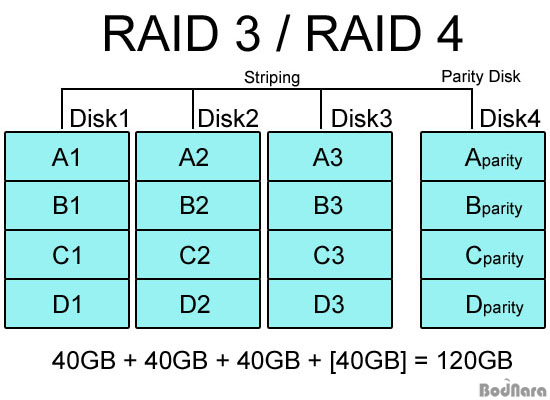
RAID 0+1과는 다르게 패리티 정보 기록용 하드 1개만을 제외한 나머지 하드를 모두 스트라이핑으로 묶어 사용하게 되므로 저장 용량에서도 유리하며, 패리티 정보를 별도의 디스크에 저장하므로 스트라이핑 하드 가운데 1개가 고장나도 패리티 정보 디스크를 통해 복구가 가능하다. 하지만 패리티 디스크 쪽도 데이터를 갱신해줘야 하므로 느려질 수 있으며 패리티 디스크가 고장나면 문제가 생길 수 있다. 스트라이핑과 달리 패리티 정보 저장 및 추후 복구를 위해 XOR 연산이 필요하며, 이 때문에 고가의 RAID 컨트롤러는 XOR 연산을 담당하는 프로세서를 따로 장착하고 있다.
RAID 5
RAID 5는 RAID 3, 4에서 별도의 패리티 정보 디스크를 사용함으로써 발생하는 문제점을 보완하는 방식으로 패리티 정보를 스트라이핑으로 구성된 디스크 내에서 처리하게 만들었다. 물론 패리티 정보는 데이터가 저장된 디스크와는 물리적으로 다른 디스크에 저장되도록 만들어 1개의 하드가 고장 나더라도 남은 하드들을 통해 데이터를 복구할 수 있도록 했다. 최소 3개부터 구성이 가능하며 하드 1개 용량만 빠지게 되므로 미러링으로 처리되는 RAID 1보다 저장 공간도 크다.
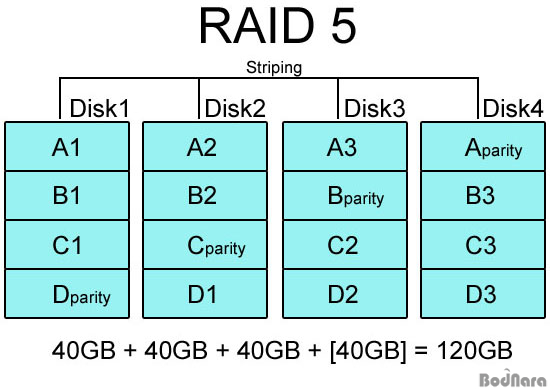
패리티 정보가 데이터가 저장된 디스크와는 다른 디스크에 저장되기 때문에 위의 RAID 5 구성에서 만약에 3번 하드(Disk3)가 고장날 경우 A3, C2, D2, 데이터는 다른 하드에 별도로 저장된 패리티 정보를 통해서 복구하고 B 패리티 정보는 나머지 하드에 있는 B1, B2, B3 데이터를 토대로 다시 작성할 수 있다. 그러나 별도로 패리티 정보를 저장하는 작업을 해야 하므로 RAID 1보다 쓰기 성능이 떨어진다.
RAID 3, 4와 달리 패리티 정보가 저장된 디스크가 따로 없어 패리티 디스크 고장과 같은 문제에서 자유롭고 실제 서버/워크스테이션에서 가장 많이 사용되는 방식이기도 하다. 보드나라 서버 역시 3개의 하드로 RAID 5를 구성하고 있다.
RAID 5 역시 XOR 연산을 필요로 하기 때문에 PCI 방식의 보급형 RAID 컨트롤러 카드나 데스크탑 메인보드의 내장 RAID 컨트롤러에서는 그 동안 거의 지원하지 않았던 규격이기도 하지만, 컴퓨터 성능이 올라간 요즘에는 메인보드 사우스브릿지 칩셋에 RAID 5 기능을 넣는 추세로 가고 있다.
RAID 6
RAID 6는 RAID 5와 같은 개념이지만 다른 드라이브들 간에 분포되어 있는 2차 패리티 정보를 넣어 2개의 하드에 문제가 생겨도 데이터를 복구할 수 있게 고안되었다. 이론상 하드 3개부터 만들 수 있지만 이럴 경우는 1개의 하드에 저장될 용량을 2개의 하드로 패리티 정보를 저장하는 꼴이므로 전체 용량의 1/3만 사용 가능하게 된다. 따라서 보통 4개 이상의 하드 디스크로 구성하며 RAID 5보다 더욱 데이터 안정성을 고려하는 시스템에서 사용한다.
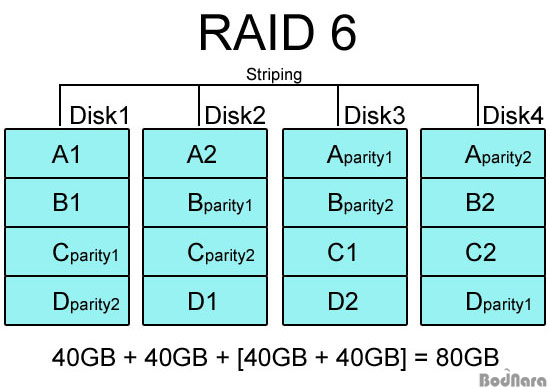
위의 이미지처럼 40GB 하드 4개로 RAID 6를 구성하면 패리티 정보를 저장하는데 2개 분량의 용량을 잡아먹기 때문에 실제 사용 가능한 용량은 절반에 불과하지만 4개의 하드를 스트라이핑으로 묶었기 때문에 RAID 0+1이나 RAID 10(1+0)보다 성능은 더 높고 신뢰성도 우수하다. 하지만 패리티 정보를 2중으로 저장하면서 읽기 성능은 RAID 5와 비슷하지만 쓰기 작업 구현이 아주 복잡해서 일반적으로 잘 사용되지는 않는다.
RAID 0+1과 RAID 10(1+0)
RAID 0+1과 RAID 10(1+0)은 RAID 0(스트라이핑)과 RAID 1(미러링) 방식을 혼합해 만들어졌다는 점에서는 매우 비슷하게 보여진다. 특히 서버/워크스테이션이 아닌 일반 사용자의 PC로 RAID를 구성한다면 많아야 4개 정도까지 묶기 때문에 RAID 0+1과 RAID 1+0을 헷갈릴 수도 있으며 실제 RAID 0+1을 RAID 10으로 표기하는 곳도 많이 있다. 필자 역시 이 둘을 혼동하는 사람 중에 하나였는데, 두 방식은 어느 쪽을 먼저 묶고 나중에 묶느냐에 따라 다르다고 한다.
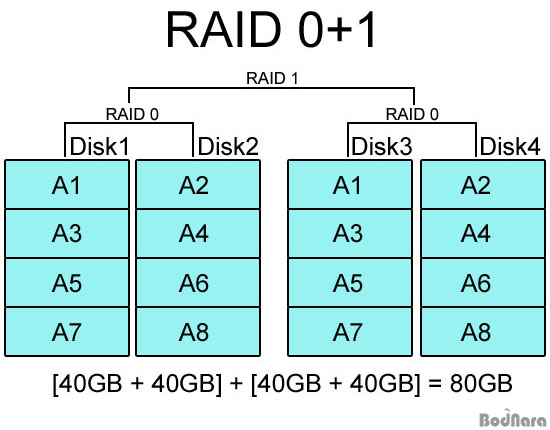
RAID 0+1은 이름 그대로 RAID 0과 RAID 1을 합쳐놓은 방식이다. RAID 0으로 묶은 하드 디스크를 최종적으로 RAID 1로 구성하기 때문에 일반 RAID 1 구성보다 높은 성능을 낼 수 있으며 한쪽 RAID 0에 들어가는 하드들이 모두 고장난다고 해도 나머지 RAID 0 하드를 통해 정상 동작 및 데이터 복구를 할 수 있다.
그래도 RAID 1이 들어가므로 전체 하드 디스크 용량의 절반 밖에 사용하지 못한다는 단점은 같지만, 성능과 안정성을 동시에 추구할 수 있는데다 따로 패리티 정보를 사용하지 않기 때문에 패리티 정보를 별도로 처리할 필요가 없다. 또한 RAID 기능을 지원하는 웬만한 메인보드 컨트롤러 및 보급형 RAID 카드에서 RAID 0+1을 기본 지원하고 있어 RAID 3, 4와 달리 고급형 컨트롤러가 필요하지 않다.
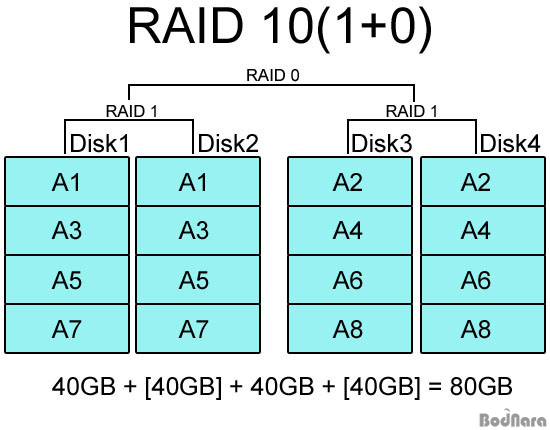
이와 달리 RAID 10(1+0)은 RAID 1로 구성된 하드들을 최종적으로 RAID 0 방식으로 스트라이핑해서 성능을 높이게 된다. 역시 RAID 1의 미러링을 기본으로 하고 있으므로 하드 1개가 고장나도 그와 함께 미러링 된 하드를 통해 데이터 복구가 가능하다.
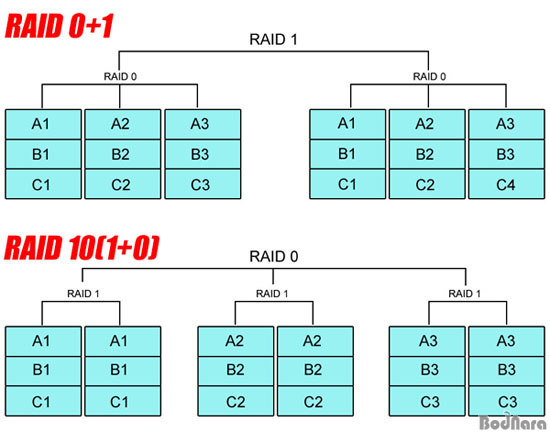
RAID 0+1과 RAID 10은 4개의 하드 디스크로 RAID를 구성할 경우 용량이나 구조에서 별 차이가 없어 보이지만 6개 이상의 하드를 사용하게 되면 위와 같은 차이가 생긴다. RAID 0+1은 RAID 0으로 구성된 하드들을 최종적으로 RAID 1로 묶는 것이라 각각 3개씩 하드가 나눠지며, RAID 10은 2개씩 RAID 1으로 묶여있는 하드들이 RAID 0으로 구성된다.
RAID 0+1은 양쪽 RAID 0 구성 중 하나씩 고장이 나면 전체 데이터가 손실되고, RAID 10은 미러링 된 하드 2개가 동시에 고장 날 경우 전체 데이터가 날라간다. 물론 그 대신 RAID 0+1은 미러링 된 한쪽이 하드 전체가 망가져도 데이터를 살릴 수 있고, RAID 10도 각 RAID 1 묶음에서 하나씩이 고장이 나도 이상없이 동작한다.
그러나 RAID 0+1의 경우 1개의 하드만 고장나서 복구해도 다른 RAID 0 구성에서 나머지 하드까지 데이터 전체(A1~3, B1~3, C1~3)를 복구해야 하지만, RAID 10으로 만든 시스템은 고장난 하드가 A2, B2, C3 가 저장된 하드 1개라고 하면 미러링으로 묶인 하드를 통해 A2, B2, C2 데이터만 복구하면 되므로 실제로 운용하는데는 RAID 10이 훨씬 유리하다.
JBOD (Just Bunch of Disks)
제이비오디(JBOD)는 Just Bunch of Disks의 약어로 사실은 스트라이핑이나 미러링 방식을 쓰지 않았기 때문에 RAID 규격이라고 할 수 없다. 다만 여러 대의 하드 디스크를 묶어 하나의 하드처럼 보이게 만든다는 점에서 RAID와 비슷하기 때문에 함께 쓰이고, RAID 지원 컨트롤러에서 JBOD 역시 지원하는 일이 많은 것이다.
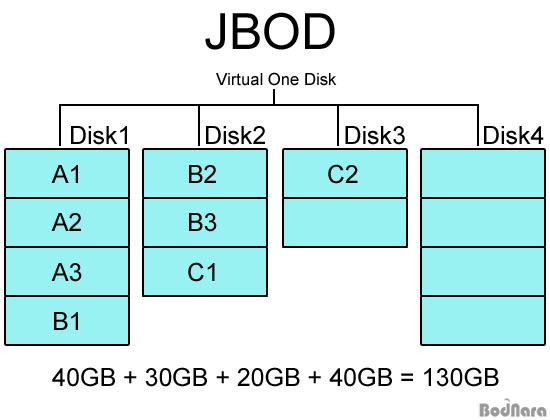
JBOD는 단순히 물리적인 여러 하드를 모아서 하나의 큰 용량을 제공하는 하드처럼 보이게 만드는 방식으로 스패닝(Spanning)으로도 불린다. 디스크 전체 용량을 사용한다는 점에서 RAID 0과 같지만 RAID 0처럼 데이터를 분산 저장하는게 아니라 디스크 순서대로 저장하기 때문에 대용량 디스크를 만들 수 있지만 실제 성능 향상은 없다. 그러나 디스크 종류/용량에 제한을 받게 되는 RAID 규격과 달리 각기 다른 용량의 디스크도 묶을 수 있다는 장점이 있다.
RAID 1.5
RAID 1.5는 RAID 비표준 규격 가운데 하나로 RAID 컨트롤러 칩셋을 만드는 회사 중 하나인 Highpoint에서 만든 것이다. RAID 15라고 불리기도 하는 이 규격은 최소 4개의 하드가 필요한 RAID 0+1 구성을 단 2개의 하드로 구성하도록 만들었다.
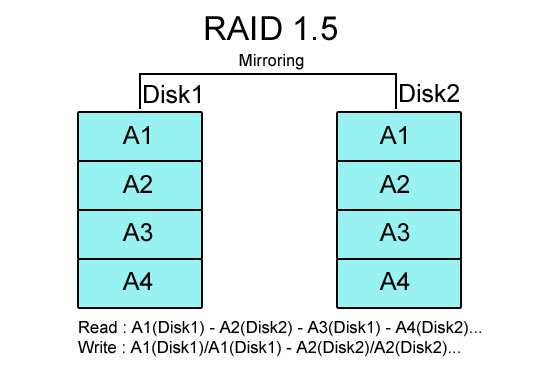
RAID 1.5의 동작 원리는 읽기는 RAID 0 모드로 읽기 성능을 향상시키고 쓰기 모드일 때는 RAID 1 방식처럼 2개의 디스크 모두 데이터를 기록해 안정성을 높인다는 것이다. 일단 하드 디스크의 구성은 기본적으로 미러링으로 만든 RAID 1과 같지만, 읽기에서 RAID 0처럼 미러링 된 2개의 하드에서 다른 부분을 동시에 읽어서 시간을 절약하게 된다고 한다. 위의 이미지가 RAID 1.5의 정확한 구조를 나타낸 것은 아니지만 Read, Write 부분을 보면 RAID 1.5가 어떤 방식으로 동작하는지 참고하는데 도움이 될 것이다.
하지만 쓰기 속도에서 RAID 1과 같으므로 읽기/쓰기가 반복되는 작업에서 RAID 0 만큼 체감 성능 향상을 느끼기 어려운데다 전체 하드 용량의 절반만 쓸 수 있다는 점에서 RAID 1과 같다. 어차피 2개의 하드로 RAID를 구성해야 한다면 RAID 0, RAID 1 외에는 다른 방법이 없기 때문에 RAID 1.5는 성능과 안정성에 타협을 본 방식이라 할 수 있지만 RAID 1.5를 지원하는 컨트롤러나 메인보드가 있어야 하므로 일반적으로 널리 사용되진 않는다. (예전에 보드나라에서 리뷰했던 DFI 메인보드 중 일부가 Highpoint RAID 컨트롤러를 달아 RAID 1.5를 지원했었다)
Intel Matrix RAID
인텔 매트릭스 레이드(Intel Matrix RAID)는 인텔 ICH6R부터 들어간 RAID 규격으로 RAID 1.5와 마찬가지로 2개의 하드 디스크로도 RAID 0과 RAID 1을 구성할 수 있도록 한 것이다. 하지만 미러링된 RAID 1 디스크를 기반으로 하는 RAID 1.5와 다르게 2개의 하드 디스크를 수평으로 묶어서 2개의 파티션(Partition)을 만들어 한 쪽은 RAID 1으로 구성하고 다른 한쪽을 RAID 0으로 만들어 2개의 하드처럼 쓰게 된다. 물론 Matrix RAID 기술은 2개의 하드를 위한 것이 아니므로 인텔에서는 4개의 하드로 같은 방식의 RAID 0 / RAID 1 파티션을 만들어 낼 수 있다고 설명한다.
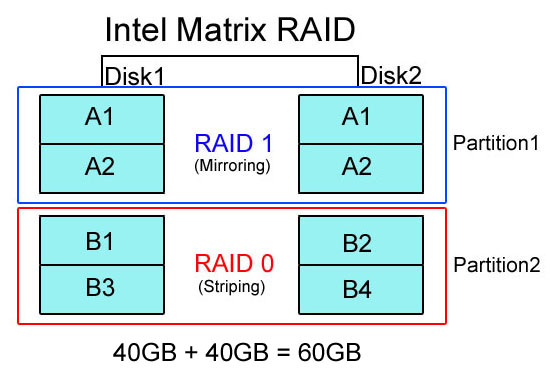
매트릭스 RAID를 구성하면 운영체제에서 각 파티션이 구분되어 2개의 하드 디스크로 잡히게 되는데, 용량은 RAID 1로 만든 쪽은 실제 묶인 하드 용량의 절반, 그리고 RAID 0 쪽은 당연히 묶인 하드 용량을 온전히 사용할 수 있어 단순한 RAID 1, RAID 1.5 방식보다 용량이나 운용면에서 이득을 준다.
중요 데이터가 있는 부분은 RAID 1로 보호하고 애플리케이션 실행처럼 빠른 하드 성능이 요구되는 쪽은 RAID 0으로 구성된 파티션에 설치해 실행하므로 성능과 용량, 그리고 데이터 보호까지 적절하게 만족시키는 타협점인데다 2개의 하드 디스크만으로 구성이 가능하기 때문에 하드가 많지 않은 일반 유저들이 데스크탑 PC로 구성하기에 적당하다. 또한 인텔 매트릭스 레이드를 지원하는 메인보드들에서 호환되기 때문에 특별한 문제가 없다면 ICH6R에서 ICH9R까지 같은 매트릭스 레이드 구성을 보존해준다고 알려지고 있다.
하지만 비표준 RAID 규격으로 일반 RAID 컨트롤러에서 사용할 수 없고 인텔 메인보드만 지원하기 때문에 업그레이드 범위가 제한된다는 단점은 있다. 굳이 Matrix RAID라는 용어를 쓰지 않더라도 일부 RAID 컨트롤러는 전체 RAID 볼륨 용량을 나누는 방법으로 2개의 하드에 RAID 0, 1을 따로 구성할 수 있다.
| 
 hanterm_color_schemes.xcs
hanterm_color_schemes.xcs






























